شبکه های پیچیده یکی از دانشهای نوین است که به بررسی ارتباطات و جریان اطلاعات میپردازد. این شبکه ها گستره ی وسیعی از شبکه های اجتماعی گرفته تا شبکه ی ارتباطات هوایی را شامل می شوند. در علم شبکه های پیچیده، نکات مشترک و متفاوت شبکه های موجود به صورت انتزاعی بررسی می شوند.
شبکه های پیچیده
شبکه های مختلفی در اطراف ما وجود دارد. شبکه های پیچیده، یک انتزاع از این شبکه ها برای بررسی خاصیت های مشترک و یا متفاوت این شبکه ها است. با گسترش توان رایانه ها امکان تولید مجموعه داده های مختلفی از شبکه های مختلف به وجود آمده است. مثلا در مورد شبکه ی اینترنت در سطح سیستمهای خودمختار، این داده ها شامل ارتباطات بین شبکه های خودمختار است. در اینمورد تعداد گره ها در حدود چند هزار گره است. در مورد شبکه های اجتماعی برخط، تعداد گره ها گاه به چندین میلیون نیز افزایش می یابد. نظریه ی شبکه ها را می توان علم روشهایی برای نمونه گیری، نمایش، تجسم، مدل سازی و به طور کلی بررسی و تحلیل داده های با این حجم بال دانست

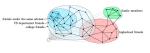
شکل ۱ نمونه ی کوچکی از شبکه ای پیچیده است. با حذف جزئیات و مجرد کردن این شبکه ها، خواص مربوط به ارتباطات این شبکه را بررسی می کنیم. مثلا در شکل ۱ که مربوط به شبکه ی ارتباطات پست الکترونیکی گروهی از افراد است، هر رنگ نشان دهنده ی بخشی است که یک گره به آن متعلق است. سایر جزئیات به طور کامل حذف شده است. تجرید شبکه های پیچیده ی مختلف، امکان بررسی دقیق تر آن ها را ممکن می سازد.
مثا لهایی از شبکه های پیچیده
شبکه های پیچیده ی متعددی وجود دارند که توسط محققان حوزه های مختلف بررسی میشوند. در این قسمت مثال هایی از شبکه های پیچیده ی مهم که بیشتر مورد توجه اند آورده می شود.
شبکه های اجتماعی
در شبکه های اجتماعی انسان ها گره و ارتباطات بین آن ها یال در نظر گرفته میشوند. بنابراین یال ها میتوانند معرف روابط مختلفی مانند دوستی یا همکاری باشند. با به وجود آمدن امکان ارتباط در دنیای مجازی، اکنون مجموعه داده های قابل بررسی و اندازه گیری برای این شبکه ها به وجود آمده است. به عنوان نمونه، می توان به شبکه ی ارسال پست الکترونیکی توسط کارمندان یک شرکت یا ارسال پیامک بین مشتر ی های یک سرویس دهنده ی تلفن همراه اشاره کرد. یکی از مجموعه داده های معروف و استاندارد در این بخش
شبکه ی همکاری بین محققان برای نوشتن مقاله است. برخی از اهداف بررسی این شبکه ها عبارتند از پیدا کردن رو شهایی برای جلوگیری از پخش فراگیر بیمار یها، پیدا کردن روشی برای کنترل انتشار شایعات و اطلاعات و حتی پیدا کردن راه های بهتر برای تبلیغ کالا در بین انسان های یک شبکه ی اجتماعی خاص.
شبکه های حمل و نقل
شبکه های حمل و نقل مانند راه های جاده ای، ریلی و هوایی نقش مهمی در زندگی امروز دارند. در این شبکه ها میتوان گره ها را ترمینال ها و فرودگاه ها فرض کرد و یال ها را راه های زمینی و هوایی بین این گره ها در نظر گرفت. یکی از اهداف اصلی بررسی این شبکه ها کاهش هزینه ی ایجاد راه های جدید یا حذف راه های قدیمی در حین حفظ کارآیی شبکه است.
اینترنت
بررسی خصوصیات ارتباطات فیزیکی مسیریا بها، رایانه ها و سوییچها امری بسیار دشوار است. یکی از مشکلت اصلی، نرخ رشد نمایی این شبکه است. مشکل دیگر، ناهمگونی اینترنت به علل تکنیکی است. تکنولوژیهای مختلف ارتباطی با هم ادغام شده اند و با کمک TCP/IP امکان ارتباط بین گره ها را می دهند، اما رفتارهای بسیار متفاوتی از گره های آن بروز میکند. همچنین باید توجه داشت که اینترنت از روی یک نقشه ساخته نشده است و جستجوی نحوه ی ساخت آن مشکل است. همین مشکل باعث شده است که بررسی های انجام شده روی اینترنت بیشتر در سطح سامانه های خود مختار باشد. در این سطح تنها ASها و ارتباطات بین آن ها دیده می شود. یکی از اهداف بررسی این شبکه ها بررسی نحوه ی کارکردن اینترنت و شبیه سازی آن به عنوان بستری برای آزمایش پروتکل های جدید است.
شبکه ی جهانی وب
شبکه ی جهانی وب مشهورترین شبکه بر بستر ساختار فیزیکی اینترنت است. امروزه این شبکه نقش مهمی در زندگی روزمره ی انسان ها دارد. این شبکه بسیار موفق و مورد قبول بود. به همین علت رشد بسیار سریع و غیر قابل مدیریتی داشت. به طوری که امروزه حتی تخمین تعداد صفحات وب کار سختی است. کار بررسی صفحات وب و پیوندهای بین آن ها توسط برنامه های پویشگر روی وب انجام می شود. اطلاعات به دست آمده از بررسی این شبکه برای جستجوی صفحات وب استفاده میشود. یال های این شبکه ی پیچیده جهت دار هستند. به این مفهوم که گره ی اول پیوندی به گره ی دوم دارد.
شبکه های زیستی
یکی از شبکه های زیستی که دانشمندان علم زیست شناسی آن را بررسی می کنند شبکه ی زیستی است که به بررسی ارتباطات بین سلول های مغز و یا ژنومها می پردازد. بسیاری از پیچیدگی های سامانه های زیستی به علت وجود چنین شبکه هایی از اجزای ساده و تک سولی است. بنابراین برای بررسی این سامانه زیستی پیچیده باید علاوه بر شناختن اجزای سازنده ی آن، ارتباطات بینشان و شبکه ی تشکیل شده از این اجزا را شناسایی کرد.
مثالهایی از سیستمهای پیچیده در طبیعت و جامعه وجود دارد؛ مانند: مغز، دستگاه ایمنی بدن، سلولهای بیولوژیکی، شبکه های متابولیکی، کلونی مورچه، اینترنت و وب، داد و ستد اقتصادی و شبکه های اجتماعی انسانی. هیچ تعریف رسمی از سیستم های پیچیده وجود ندارد. به طور غیر رسمی، یک سیستم پیچیده که یک شبکه بزرگی از مولفه های نسبتاً ساده است، بدون هیچ کنترلی، رفتارهای پیچیدهای را نشان میدهد. البته واژه ها در این تعریف یا دقت زیادی تعریف نشده اند. مولفه های نسبتاً ساده به این معنا است که نقش وظیف های آنها در رفتار جمعی سیستم، ساده است. برای مثال، یک نرون (یاخته عصبی) یا یک مورچه موجودیت های پیچیده ای هستند، هر چند که نقش وظیفه ای آنها در مغز یا کلونی نسبتاً ساده است.
ولی انواع دیگری از شبکه ها هم وجو دارد که مثال خوبی از شبکه های اجتماعی هستند.
شبکه دوستان: در اینجا نودها نشان دهنده افراد و یال ها نشان دهنده ارتباط میان آنهاست. یال در این نوع شبکه ها معمولا وزن دار نیستند که نشان می دهند این نودها دوست هستند یاخیر. اگر نیاز باشد قدرت این ارتباط نشان داده شود می توان از یال های وزن دار استفاده کرد.
از دیگر انواع شبکه های اجتماعی می توان به شبکه های تلفن، شبکه های ایمیل و Collaboration Networks هم اشاره کرد.
Community Detection in Social Networks
اجتماعات ساختار های اصلی شبکه ها هستند که اشخاص یا رئوس در یک اجتماع نسبت به اشخاص در سایر اجتماعات بصورت متراکم تری به هم متصل شده اند. اشخاص به یکدیگر متصل هستند زیرا یا همدیگر را می شناسند یا مشخصه های مشترکی دارند بنابراین می توان گفت اگر افراد در یک اجتماع باشند مشخصه های مشترک و مشابه بیشتری دارند. تشخیص اجتماع مهم است زیرا اجتماع نسخه کوچکی از یک گراف کامل است که خصوصیات بسیار مشابه آن گراف را نشان می دهد. بنابراین بررسی چند اجتماع ممکن است ما را قادر سازد کل شبکه را بشناسیم. این خصوصیت بسیار مفید است به خصوص زمانی که شبکه یک داده بزرگ از دنیای واقعی باشد. تشخیص اجتماع عرصه های کاربردی متنوعی در دنیای واقعی دارد. در بازاریابی، امنیت و عرصه های علمی مفید است. پیشنهاد سرویس ها و محصولات مشابه به افرادی که در یک اجتماع هستند و استفاده از اجتماع افراد به عنوان مشخصه ای برای سیستم های توصیه گر دو مورد از کاربردهای مهم و شناخته شده هستند. مثال دیگری که در زمینه کاربرد تشخیص اجتماع در شبکه های اجتماعی وجود دارد این است که استفاده از تشخیص اجتماع در شبکه های اجتماعی برای افشا سازی رویدادهای fraud و سایر نشتی های مشکوک پول با ایجاد شبکه ای از مشتریانی که از یک اجتماع ارتباطات text messages یا تلفنی استفاده میکنند و تعیین ساختارهای اجتماع قابل انجام است.
به عنوان مثالی دیگر در عرصه های آکادمیک می توانیم نشان دهیم که تفکیک شبکه ها به اجتماعات می تواند به محققان برای جستجوهای تحقیقاتی خود در یک فیلد تخصصی کمک کند. مطالعاتی نیز در زمینه پیدا کردن مجرمین مخفی در شبکه ها که اطلاعات کمی در مورد هویت آنها وجود دارد انجام شده است. در این نوع شبکه ها از آنجایی که داده های زیادی برای دسته بندی اشخاص وجود ندارد ارتباطات میان موجودیت ها مهم می شود.
اجتماع را می توان به عنوان خلاصه ای از کل شبکه در نظر گرفت بنابراین بصری سازی و درک آن ساده تر می شود.
گاهی اوقات اجتماعات می توانند مشخصه ها و ویژگی ها را بدون افشای اطلاعات خصوصی افراد به ما بدهند. ارتباطات میان افراد و اشیا را می توان بصورت شبکه های اجتماعی نشان داد.
Partitional Clustering
اولین مطالعات کامپیوتری برای پیدا کردن اجتماعات مشابه اشیا بر اساس آمار و داده کاوی بود. مهمترین آنها مطالعاتی با استفاده از روش های partitional clustering مانند k-means clustering، شبکه های عصبی و multidimensional scaling بود.
Hierarchical Clustering
Hierarchical Clustering یکی از محبوب ترین روش های تشخیص اجتماع برای شبکه های اجتماعی است. برای گرافی با N راس و ماتریس مشابهت A ، hierarchical clustering برای شبکه های عمومی بصورت زیر است:
۱٫ اختصاص یک شماره اجتماع منحصر به فرد به همه N راس به صورتی که N اجتماع مختلف داشته باشیم
۲٫ پیدا کردن دو اجتماع از همه نزدیک تر و ادغام آنها به یک اجتماع
۳٫ محاسبه مجدد شباهت میان کلاسترهای قدیمی و جدید
۴٫ تکرار گام های دوم و سوم تا زمانی که تمام رئوس در یک اجتماع قرار داده شوند
۵٫ درخت سلسله مراتبی حاصل که dendrogram هم نامیده می شود بصورت افقی بریده شده و پارتیشن های نهایی تولید می شوند.
این طور که مشخص است تشخیص اجتماع همان کلاسترینگ است پس چرا کارهای زیادی روی آن انجام شده است (KDD، WWW). پاسخ این است که داده های شبکه نسبت به روش های کلاسترینگ کلاسیک دچار چالش می شوند.
کلاسترینگ بر روی فاصله و یا ماریس مشابهت کار می کند (-means, hierarchical clustering, spectral clustering). داده های شبکه معمولا گسسته هستند و نیاز به الگوریتم هایی است که از مشخصه های گراف به طور مستفیم استفاده کنند (k-clique, quasi-clique, vertex-betweenness, edge-betweenessetc). شبکه دنیای واقعی مقیاس بزرگی دارد.
در نتیجه دو روش تشخیص اجتماع دیگر معرفی شد. کلاسترینگ بر اساس shortest-path betweenness و کلاسترینگ بر اساس modularity شبکه.
ایده اصلی این دو روش
یک استراتژی تقسیم ساده و سپس تکرار:
۱٫ یک یال بین اجتماعات پیدا کنید
۲٫ آن را حدف کنید
۳ . بررسی کنید که آیا جزئی از اتصال خارج شده که نشان دهنده اجتماع است
نحوه محاسبه inter-community: اگر دو اجتماع توسط چند یال inter-community متصل شده اند آنگاه تمام مسیرهای یک اجتماع به دیگری باید از یال ها عبور کنند
سایر معیارها
Edge Betweenness: کوتاهترین مسیرها میان هر دو نود را پیدا کنید و بشمارید که چند مسیر از میان هر یال عبور کرده است.
Random Walk betweenness.
Current-flow betweenness
محاسبه Shortest-path betweenness می تواند پر هزینه باشد محاسبه کوتاهترین مسیر میان هر دو راس O(m) است و O(n^2) زوج داریم. میتوان آن را به O(mn) بهینه کرد. در حالت ساده که تنها یک مسیر کوتاه میان منبع S و یک راس دیگر وجود دارد، این مسیرها یک درخت ایجاد میکنند.
Multiple shortest path: ابتدا تعداد مسیرهایی که از منبع به سایر رئوس می رود محاسبه کنید سپس وزن مناسبی به تعداد مسیرها اختصاص دهید.
Sum of the betweenness: تعداد رئوس قابل دسترس
Modularity Spectral Clustering: سعی در مینیمم کردن تعداد رئوس میان گروه ها می کند. ماژولاریتی شماره یال هایی را در نظر می گیرد که کمتر از مقدار مورد انتظار هستند. محمد محمدنژاد
اگر تفاوت به طرز قابل ملاحظه ای بزرگ باشد یک ساختار اجتماع داخل آن وجود دارد. هرچه بزرگتر بهتر.
محاسبه ماژولاریتی:
انتظار می رود ماژولاریتی تعداد کلاسترها را تعیین کند.
Graph Partitioning
در علم کامپیوتر Graph Partitioning فرایندی است که شبکه را به گروه هایی با اندازه کوچک تر تقسیم می کند و در عین حال سعی در حداقل کردن تعداد یالهای میان این گروه ها دارد. بسیاری از روش های Graph Partitioning بر اساس تقسیم گراف به دو گروه مجزا عمل می کنند : روش spectral bisection که از مارتیس لاپلاس گراف و بردارهای ویژه آن استفاده می کند و الگوریتم Kernighan_Lin که سعی در بهینه کردن ساختار اجتماع بر روی یک پارتیشن اولیه از گراف با روش حریصانه دارد.
Girvan-Newman Algorithm
الکوریتم بعدی الگوریتم Girvan-Newman است که در آن از الگوریتم Divisive استفاده شده است. در این الگوریتم از خصوصیت Betweenness شبکه های اجتماعی استفاده می شود.
Algorithm of Duch and Arenas
الگوریتم بعدی الگوریتم Duch and Arenas است که روش جدیدی برای تعیین ساختارهای اجتماعات در شبکه های بزرگ و پیچیده است. این روش بر اساس بهینه سازی مقدار ماژولاریتی است. در گام اول کل گراف به دو اجتماع مساوی تصادفی تقسیم می شود. در هر گام نودی که کمترین مقدار fitness را دارد از یک اجتماع به دیگری منتقل می شود و سپس fitness نودهای همسایه محاسبه می شود. این فرایند تا رسیدن به Modularity Score Q ماکزیمم ادامه می یابد. سپس تمام لینک های میان دو اجتماع حاصل پیدا شده و همین روال بر روی هر اجتماع تکرار می شود تا زمانی که Modularity Score Q را نتوان دیگر بهتر کرد.
Algorithm of Clauset et. al.
الگوریتم بعدی الگوریتم پیشنهاد شده توسط Clauset، Newman و Moore است که نوعی روش کلاسترینگ agglomerative hierarchical می باشد. از modularity score Q پیشنهادی توسط Girvan and Newman هم به عنوان معیاری برای بهینه سازی ساختارها استفاده می کند.
Newman›s Spectral Algorithm
الگوریتم Newman در ماژولاریتی و ساختار اجتماعی در شبکه ها، نسخه تخصصی از روشهای Spectral برای گرافهای شبکه اجتماعی است.
در این الگوریتم با دادن یک گراف می خواهیم نودها را به دو مجموعه تقسیم کنیم به طوری که این تقسیم یا مجموعه یال هایی که نودها را متصل می کنند در مجموعه های مختلف مینیمم شوند.
منبع:
ماهنامه کامپیوتری رایانه
تحلیل شبکههای اجتماعی روابط اجتماعی را با اصطلاحات رأس و یال مینگرد. رأسها بازیگران فردی درون شبکهها هستند و یالها روابط میان این بازیگران هستند. انواع زیادی از یالها میتواند میان رأسها وجود داشته باشد. نتایج تحقیقات مختلف بیانگر آن است که میتوان از ظرفیت شبکههای اجتماعی در بسیاری از سطوح فردی و اجتماعی به منظور شناسایی مسائل و تعیین راه حل آنها، برقراری روابط اجتماعی، اداره امور تشکیلاتی، سیاستگذاری و رهنمون سازی افراد در مسیر دستیابی به اهداف استفاده نمود.
در سادهترین شکل یک شبکهٔ اجتماعی نگاشتی از تمام یالهای مربوط، میان رأسهای مورد مطالعهاست. شبکهٔ اجتماعی هم چنین میتواند برای تشخیص موقعیت اجتماعی هر یک از بازیگران مورد استفاده قرار گیرد. این مفاهیم غالباً در یک نمودار شبکهٔ اجتماعی نشان داده میشوند که درآن، نقطهها رأسها هستند و خطها نشانگر یالها.
آنالیز شبکههای اجتماعی
آنالیز شبکههای اجتماعی (مرتبط با نظریه شبکهها) به عنوان یک تکنیک کلیدی در جامعهشناسی، انسانشناسی، جغرافیا، روانشناسی اجتماعی، جامعهشناسی زبان، علوم ارتباطات، علوم اطلاعات، مطالعات سازمانی، اقتصاد و زیستشناسی مدرن همانند یک موضوع محبوب در زمینهٔ تفکر ومطالعه پدیدار شدهاست.
بالغ بر یک قرن است که مردم، شبکهٔ اجتماعی مجازی را برای اشارههای ضمنی به مجموعه روابط پیچیده میان افراد درسیستمهای اجتماعی در تمامی مقیاسها از روابط بین فردی گرفته تا بینالمللی مورد استفاده قرار میدهند. در سال ۱۹۴۵ J. A. Barnesبرای نخستین بار از اصطلاح قاعدهمند برای مشخص کردن الگوهایی از رشتهها استفاده کرد که مفاهیم را مشخص میکنند و به صورت رایج توسط عموم و دانشمندان علوم اجتماعی مورد استفاده قرار میگیرد: گروههای محدود (مانند: قبایل و خانوادهها) و طبقات اجتماعی (مانند: جنسیّت و قومیت).
آنالیز شبکههای اجتماعی از طریق احکام نظری و روشها و تحقیقهای مربوط به آن از یک صنعت ضمنی به معبری تحلیلی برای پارادایمها تغییر یافتهاست. برهانهای تحلیلی از کل گرفته تا جزء؛ از ساختار گرفته تا روابط و افراد، از اخلاق گرفته تا رفتار همگی شبکههای سراسری را مورد بررسی قرار میدهند که در آنها، همهٔ رشتهها شامل روابط ویژهای در میان جمعیتِ تعریف شدهاند و یا شبکههای فردی را مورد بررسی قرار میدهند که شامل رشتهها یی است که افراد مشخصی آنها را دارند از قبیل انجمنهای خصوصی.
گرایشهای تحلیلی متعددی آنالیز شبکههای اجتماعی را تمیز میدهند: هیچ فرضی وجود ندارد که گروهها، بلوکهای بنا کنندهٔ اجتماع هستند:این معبر برای مطالعهٔ سیستمهای اجتماعی با محدودیت کمتر باز است از اجتماعات غیر محلی گرفته تا لینکهای درون وبگاهها.
آنالیز شبکههای اجتماعی علاوه بر سروکارداشتن با اشخاص (افراد، سازمانها، ایالات) به عنوان واحدهای گسستهٔ تحلیل، برروی چگونگی ساختار رشتهها که اشخاص و روابط میان آنها را تحت تأثیر قرار میدهد نیز تمرکز میکند.
برخلاف تحلیلهایی که بر این فرض استوارند که هنجارهای اجتماعی تعیین کنندهٔ رفتارها هستند، آنالیز شبکههای اجتماعی به بررسی وسعت تأثیرگذاری ساختار و ترکیب رشتهها بر هنجارها میپردازد.
شکل یک شبکهٔ اجتماعی به تعیین میزان سودمندی شبکه برای افراد آن شبکه کمک میکند. به طور جزئی شبکههای محکم برای اعضایشان نسبت به شبکههایی که تعداد زیادی اتصالات ضعیف برای افراد خارج از شبکهٔ اصلی دارند، کمتر مفید واقع میشوند. بیشتر شبکههای باز با اتصالات اجتماعی و رشتههای ضعیف، شانس بیشتری برای دسترسی به ایدهها و دستآوردهای جدید نسبت به شبکههای بسته با رشتههای طویل فراهم میآورد. به بیان دیگر گروهی از دوستان که تنها دارای ارتباط با یکدیگر هستند، اطلاعات و دستآوردهای یکسانی را به اشتراک میگذارند. اما گروهی از افراد که دارای ارتباط با بخشهای اجتماعی دیگر هستند شانس بیشتری برای دسترسی به محدودهٔ وسیعتری از اطلاعات دارند. افراد برای دستیابی به موفقیت بهتر است که با شبکههای گوناگونی ارتباط داشته باشند تا اینکه ارتباطات زیادی درون یک شبکه داشته باشند. به طور مشابه افراد میتوانند تأثیرگذاری و ایفای نقش به عنوان واسطه در برقراری ارتباط بین دو شبکه که به هم متصل نیستند را تمرین کنند. (این کار پر کردن سوراخهای ساختاری نامیده میشود)
آنالیز شبکههای اجتماعی چشمانداز متناوبی را ایجاد میکند که در آن خواص افراد نسبت به ارتباطات و رشتههای میان آنها در شبکه از اهمیت کمتری برخوردار است. این معبر ایجاد شدهاست تا برای توضیح بسیاری از پدیدههای جهان واقعی مفید واقع شود، اما مجال کمتری برای نمایندگیهای فردی باقی میگذارد تا توانمندیهای فردیشان روی موفقیت تأثیرگذار باشد زیرا بخش زیادی از این توانمندیها درون ساختار شبکه باقی میماند.
شبکههای اجتماعی برای بررسی چگونگی تأثیرات متقابل میان تشکیلات، توصیف بسیاری از اتصالات غیررسمی که مجریان را به یکدیگر متصل میکند، نیز مورد استفاده قرار گرفتهاست و در این زمینهها نیز به خوبی برقراری ارتباطات فردی میان کارمندان در سازمانهای مختلف عمل میکند. شبکههای اجتماعی نقش کلیدی در موفقیتهای تجاری و پیشرفتهای کاری ایفا میکنند. شبکهها راههایی را برای شرکتها فراهم میکند که اطلاعات جمعآوری کنند، از رقابت بپرهیزند و حتی برای تنظیم قیمتها و سیاستها با هم تبانی کنند.
مدلهای انتشار اطلاعات
دو مدل اولیه توسط ریچاردسون و دومینگوس ارائه شد که به آنها اشاره خواهیم کرد.
مدل انتشار مستقل
در این مدل کل شبکه اجتماعی به صورت یک گراف نمایش داده میشود که در آن رئوس نشا ن دهنده افراد و یالها نشا ن دهنده ارتباط میان آنها هستند. برخی از راسها به صورت پیش فرض فعال و بقیه غیرفعال هستند. وزن یالها عددی میان صفر و یک است که نشان دهنده احتمال فعال شدن آنها است. هرگاه راسی مانند Vفعال میشود با احتمالی میتواند راسهای همسایه خود را فعال کند. این احتمال برابر وزن یال ارتباطی میان راسV و راسU (راسی که V شاید بتواند آن را فعال کند) P(U,V) است. این فعال سازی با احتمالی که گفته شد تنها یه بار صورت م یگیرد، به این معنی که اگر با احتمال مربوط راس V نتوانست راس u را فعال کند دیگر راسV شانسی برای اثرگذاری بر راس U نخواهد داشت.
مدل حد آستانه خطی
در این مدل نیز مانند مدل انتشار مستقل، شبکه اجتماعی با یک گراف مدل میشود که افراد به صورت راس و ارتباط میان افراد به صورت یال نمایش داده میشود. از طرفی هر راس دارای دو وضعیت فعال و غیرفعال است. احتمال اثرگذاری فرد V بر فرد U را با وزن بین دو یال، که با bv,w نمایش میدهیم، بیان میشود. این وزن یا همان احتمال به گونهای است که باید مجموع جمع همسایهها کمتر از ۱ باشد: هر راس v دارای یک حد آستانه است که بین بازه [۰٬۱] به صورت تصادفی انتخاب م یشود، این مقدار نسبت وزنی همسایگانی از v ات که باید فعال شوند تا منجر به فعال شدن v شوند. با داشتن انتخا بهای تصادفی برای آستانهها و یک مجموعه از رئوس فعال اولیه (که در این حالت بقیه رئوس کاملاً غیرفعال هستند)، مراحل انتشار به طور قطعی در قدمهای مجزای زیر خواهد بود:
۱- در قدم t کل رئوسی که در قدم t-1 فعال بودند، به صورت فعال باقی خواهند ماند. ۲- راس v را در صورتی فعال میکنیم که جمع وز نهای همسایگان فعال آن حداقل θv باشد.
شبکههای اجتماعی اینترنتی در دنیا
استفاده از خدمات شبکههای اجتماعی، روزبهروز محبوبیت بیشتری پیدا میکند. هماکنون سایتهای شبکههای اجتماعی، بعد از پرتالهای بزرگی مثل یاهو یا اماسان موتورهای جستجو مثل گوگل، تبدیل به پراستفادهترین خدمت اینترنتی شدهاند.
خیلی از نهادهای مختلف جهانی و اینترنتی با اهداف گوناگون که مهمترین آنها تجاری و تبلیغاتی است، دست بهراهاندازی شبکههای اجتماعی زده یا درصدد خرید سهام مهمترین شبکههای اجتماعی دنیا هستند؛ مثل رقابت اخیر گوگل و مایکروسافت برسر سایت مایاسپیس و فیسبوک.
در رقابت مایاسپیس، پرکاربرترین سایت شبکه اجتماعی دنیا گوگل و در رقابت برسر فیسبوک، مایکروسافت برندهشد. ضمن اینکه یاهو هم بعد از راهاندازی نهچندان موفق «۳۶۰درجه»، به دنبال راهاندازی یک شبکه اجتماعی دیگر بهاسم «مش» است.
ناسا هم برای جذب جوانان علاقهمند به موضوعات هوافضا، یک شبکه اجتماعی را بر پایه استانداردهای نسل آینده وب و تنظیمات سایت خود راهاندازی کرد.
این شبکه اجتماعی جدید که مای ناسا نام دارد، بخشهای بسیار پیشرفتهای دارد که کاربران میتوانند از طریق آنها تصاویر و تفکرات خود را دربارهٔ موضوعات فضایی با سایر کاربران بهاشتراک بگذارند. مای ناسا یک نمونه بسیار اصلی از شبکههای اجتماعی است و یک محیط مجازی را میسازد که در آن کاربران میتوانند تمام موضوعات و مقولات مورد نظر و شخصی خود را جمعآوری کنند.
کاربران میتوانند در این شبکه اجتماعی جدید برای خود وبلاگ درست کنند و از وبلاگهایی نظیر وبلاگ یکی از مدیران ناسا که روایت بسیار شگفتانگیزی را از ماموریتهای فضایی خود نقل کردهاست، استفاده کنند.
شبکههای اجتماعی، بهخصوص آنهایی که کاربردهای معمولی و غیرتجاری دارند، مکانهایی در دنیای مجازی هستند که مردم خود را بهطور خلاصه معرفی میکنند و امکان برقراری ارتباط بین خود و همفکرانشان را در زمینههای مختلف مورد علاقه فراهم میکنند. البته در بعضی از این موارد مثل مایناسا سمت و سوی اصلی این علایق (فضا) مشخص است.
به نظر میرسد شبکههای اجتماعی در اینترنت، در آینده بیش از این هم اهمیت پیدا میکند. این شبکهها هماکنون هم روزبهروز محبوبتر میشوند. با شبکههای اجتماعی، دیگر افراد برای پیداکردن همفکران خود در موارد گوناگون تنها نیستند؛ یک دوست آرژانتینی برای تحلیل بازیهای بوکاجونیورز، یک دوست سوئدی برای صحبت در مورد فناوری اطلاعات، یک دوست فرانسوی برای صحبت در مورد فیلمهای سینمای مستقل یا یک دوست مصری برای بحث در مورد مسائل خاورمیانه.
مسلماً در دنیای حقیقی هیچگاه افراد علاقهمند، موضوعات موردعلاقه خود را به این گستردگی نمییافتند. این دلیل و شاید دلایل مشابه این، سرویسهای شبکههای اجتماعی را به یکی از مهمترین ارکان اینترنت در دو، سه سال اخیر تبدیل کردهاست.
منبع:
https://fa.wikipedia.org/wiki/
گروههای دوستان در شبکهی اجتماعی نیاز به تعریف و توضیح ندارد، شبیه به همان حلقهها و یا لیست دوستان در فیسبوک و توئیتر که به شما در سازماندهی روابط خود با افراد در شبکههای اجتماعی کمک میکنند. این حلقهها ممکن است کاملا جدا از هم باشند، و یا این که با هم همپوشانی داشته باشند و یا حتی به صورت تو در تو و سلسله مراتبی با هم ارتباط داشته باشند.
هدف از این پروژه بدست آوردن خودکار حلقههای دوستان در شبکه اجتماعی است. در واقع شما لیستی از کاربران در شبکه اجتماعی را به عنوان ورودی در اختیار خواهید گرفت و با روش و الگوریتمی که در طول پروژه توسعه میدهید، برای هر کدام از این کاربران حلقهای از دوستان احتمالی در شبکه اجتماعی را پیدا میکنید.
1. مقدمه
امروزه شبکه های اجتماعی ما بسیار گسترده و بهم ریخته شده اند و درحال حاضر هیچ راه مناسبی برای مدیریت و دسته بندی آن ها وجود ندارد. البته بعضی از شبکه های اجتماعی به کاربران این امکان را داده اند تا خودشان دوستانشان را در حلقه های اجتماعی(مانند حلقه ها در google+ و لیست دوستان در facebook و twitter ) دسته بندی کنند. بهرحال این روش راهی مناسب به نظر نمی رسد چرا که با اضافه شدن افراد دیگر به دوستان باید این حلقه ها توسط کاربران بروزرسانی گردند.
پس ما به دنبال طراحی سیستمی هستیم که قابلیت یادگیری و شناسایی افراد را داشته باشد و بتواند به صورت خودکار حلقه های اجتماعی را تشکیل داده و آن ها را بروز رسانی کند.
در این پروژه ما اطلاعات یک شخص و دوستان وی در یک شبکه اجتماعی را داریم و هدف ما پیدا کردن حلقه های اجتماعی شخص مورد نظر است که هر حلقه زیر مجموعه ای از دوستان شخص می باشد.
همان طور که در شکل زیر مشاهده می شود شخص با u و دوستان وی با v مشخص گردیده اند و هدف ما پیدا کردن حلقه های نمایش داده شده است.

1.1. شرح مسئله
در این پروژه قصد داریم به بررسی روش های گفته شده در کارهای مرتبط بر روی دیتاست های مختلف بپردازیم و دقتشان را با یکدیگر مقایسه کنیم.
خروجی کار در انتها نموداری برای سنجش میزان دقت و سرعت روش های مختلف مطرح شده می باشد.
2. کارهای مرتبط
1.2. Clustering
در روش خوشه بندی یا clustering مدلی برای ایجاد حلقه ها با ویژگی های زیر تعریف می شود:
-
راس هایی که در یک حلقه قرار دارند باید ویژگی ها یا جنبه های یکسانی داشته باشند
-
حلقه های مختلف باید براساس ویژگی های متفاوتی شکل گرفته باشند مثلا حلقه ی خانوادگی یا حلقه ی افراد یک دانشگاه
-
حلقه ها می توانند با یکدیگر تداخل داشته باشند و همچنین حلقه های قوی تر نیز میتوانند داخل حلقه های ضعیف تر شکل بگیرند
ورودی این مدل برای هر کاربر مجوعه V که رئوس متصل به u ( کاربر مورد نظر ) و مجموعه E که شامل تمام یال هایی می باشد که میان مجموعه V وجود دارد به همراه پروفایل تمام اعضای مجموعه V است.
هدف این روش پیش بینی کردن مجموعه نهایی C ( حلقه های کاربر ) میباشد.
و همچنین مشخص کردن پارامتر θk
که نمایش دهنده این می باشد که حلقه بر اساس چه ویژگی یا جنبه هایی تشکیل شده است.
همچنین از پارامتر (ϕ(x,y
به عنوان نمایش دادن میزان شباهت پروفایل دو کاربر x و y استفاده شده است.
در قدم اول ابتدا هر یک از رئوس گراف را یک خوشه در نظر میگیریم و سپس از فرمولی که در زیر آمده برای تشخیص اینکه آیا دو خوشه میتوانند با هم ترکیب شوند و یا خیر استفاده میشود. این روش را تا جایی که مجموعه C تغییری نکند انجام میدهیم.
که سیگمای اول شامل تمام حلقه هایی است که هر دو راس در آن ها قرار میگیرند و سیگمای دوم بقیه ی حلقه ها را شامل می شود.
در این فرمول مقدار
αk
ضریب تناسبی برای متعادل کردن مقدار سیگما ها می باشد.
ایده این فرمول آن است که اگر مقدار پارامتر
⟨ϕ(x,y),θk⟩
که نمایش دهنده میزان شباهت دو راس با یکدیگر بر اساس ویژگی مورد نظر می باشد بالا باشد یعنی هر دو راس متعلق به یک خوشه می باشند و اگر پایین باشد یعنی متعلق به خوشه ی مورد نظر نیستند.
2.2. Infomap
در روش infomap با استفاده از روش خوشه بندی با این تفاوت نسبت به روش قبل که می تواند بر روی گراف های جهت دار ووزن دار نیز اعمال شود دو الگوریتم برای خوشه بندی داده ها ارائه می شود که به طور مختصر به شرح آن ها می پردازیم.
-
الگوریتم Two-level clustering
هسته کاری این الگوریتم خوشه بندی براساس map equation است و ابتدا هر یک از راس های گراف را یک خوشه درنظر می گیرد و در هر مرحله هرکدام از خوشه ها که شباهت زیادی با یکدیگر دارند ادغام می کند.
این روش از این نظر مناسب نیست که هر گاه دو خوشه با یکدیگر ترکیب شوند یک خوشه ی جدید به وجود می آید و اثری از خوشه های قبلی دیگر نیست و ممکن است که اگر خوشه های قبلی با خوشه های دیگری در مراحل بعد ترکیب شوند به جواب بهتر و دارای دقت بالاتری دست پیدا کنیم[2].
برای رفع این مشکل دو متد زیر در نظر گرفته شده است:
1. متد Submodule movements
این متد به ما قابلیت تجزیه ی یک خوشه به زیر خوشه هایش که در مرحله قبل تشکیل شده اند را می دهد.
2. متد Single-node movements
این متد به ما قابلیت تجزیه ی خوشه و جدا کردن یک راس و درنظر گرفتن راس به عنوان خوشه ی مستقل را می دهد. -
الگوریتم Multi-level clustering
این الگوریتم مدل کامل تری از الگوریتم قبل بوده و متد هایی که در این الگوریتم تعریف می شوند می توانند به جای تجزیه ی خوشه به یک مرحله قبل خوشه را به مقدار دلخواه تجزیه کنند.
توسط این دو متد می توان در هر مرحله و هر جا که یک خوشه ترکیب شد چک کنیم که آیا بهترین ترکیب برای خوشه بندی را انتخاب کرده ایم و یا خیر!
3.2. Martelot
روش Le Martelot نیز همانند روش های پیشین از الگوریتم های خوشه بندی اطلاعات استفاده می کند و قابل اجرا بر روی گراف های جهت دار و وزن دار می باشد.
در این روش با استفاده از Newman's modularity که فرمولی برای محاسبه میزان تفاوت های یک راس یا یک خوشه با دیگر خوشه ها می باشد به خوشه بندی اطلاعات می پردازیم.
این فرمول خوشه بندی برای حل مسئله ی تشخیص گروه ها مناسب نیست چرا که در شناسایی گروه های کوچک و متداخل ضعیف عمل می کند.
برای حل این مشکل در روش Martelot ضرایب مختلفی به میزان متفاوت بودن خوشه ها با یکدیگر در ماژولاریتی داده می شود و الگوریتم خوشه بندی را چندین بار اجرا می کند و خوشه بندی بهینه را انتخاب میکند.
4.2. Louvain
متد Louvain یک متد نسبتا سریع برای پیدا کردن گروه ها در شبکه های بزرگ است.
در این متد با استفاده از روش های حریصانه بر روی ماژولاریتی آن را بهینه کرده و به خوشه بندی راس های گراف می پردازد.
این بهینه سازی در 2 مرحله انجام می شود:
-
با بهینه سازی محلی متد به دنبال گروه های کوچک میگردد.
-
سپس با ادغام گروه های کوچک که توانایی ایجاد گروه های بزرگتر را دارند خوشه بندی را ادامه می دهد.
این مراحل را مرتبا تکرار می شود تا به مقدار ماکزیمم ماژولاریتی برسیم.

5.2.Combo
الگوریتم های جستجوی موجود برای تشخیص گروه های شبکه های اجتماعی براساس یک یا چند روش زیر کار می کنند:
-
ادغام : ادغام و ترکیب دو جامعه مشابه
-
تقسیم : تقسیم و تجزیه ی دو جامعه ی متفاوت
-
نوترکیبی : انتقال و حرکت کردن یک راس بین دو جامعه ی مجزا
الگوریتم combo با بهره گیری از هر ۳ روش بالا به حل مساله تشخیص گروه های اجتماعی می پردازد که روش انجام کار این الگوریتم را توضیح می دهیم.
پس از انتخاب شدن یک حالت اولیه از یک شبکه اجتماعی موجود(منظور از حالت اولیه ،جوامع موجود در ابتدای برنامه است که می توانند هر جوامع تصادفی انتخاب شوند و یا در ابتدای کار تمام شبکه یک جامعه در نظر گرفته شود و در مراحل بعدی تقسیم شود و یا هر کدام از رئوس یک جامعه جدا در نظر گرفته شوند و در مراحل بعد ادغام گردند) مراحل زیر تا زمانی که تابع هدف به امتیاز بالا و نتایج مطلوب دست پیدا کند انجام می شود:
-
برای هر جامعه بهترین توزیع مجدد ممکن برای تمام رئوس به جامعه ی مقصد آن ها(اگر جامعه ی مقصد موجود نباشد جامعه جدید ایجاد می گردد ) محاسبه می شود. به زبان ساده تر در این مرحله وضعیت یک جامعه بررسی می شود که آیا جامعه مشخص شده مستقل از بقیه ی جوامع موجود است یا نیاز دارد که تغییرات روی آن صورت بگیرد.
-
در این مرحله اگر جامعه نیاز به تغییر داشته باشد بهترین عمل ادغام/تقسیم/نوترکیبی انتخاب شده و اعمال می شود.
3.آزمایش و نتایج
1.3.Data Set
مجموع دادگان ورودی این مساله یک گراف شبکه است که به صورت های مختلف می تواند تعریف شود.
-
فرمت Link list
این نوع ورودی دارای N خط می باشد که به تعداد یال های گراف شبکه است و در هر خط هر یال به صورتsource target weightتعریف می شود. که source و target رئوس مبدا و مقصد را مشخص می کنند و weight نیز نمایش دهنده وزن یال است که عددی نا منفی است و می تواند نباشد که در این صورت به صورت پیش فرض مقدار ۱ در نظر گرفته می شود.
همان طور که مشاهده می شود توسط این نوع به سادگی می توان گراف های جهت دار و وزن دار را نیز پشتیبانی کرد. -
فرمت Pajek
این نوع ورودی راس ها و یال های گراف شبکه را در دو قسمت جداگانه همانند زیر در یک فایل مشخص می کند:
*Vertices N
1 "V1"
2 "V2"
3 "V3"
...*Edges M
1 2 1
1 5 0.33
4 3 0.5
2 3 1
...
در بخش رئوس که با Vertices N* مشخص می شود N نمایش دهنده ی تعداد رئوس گراف است و در N خط بعد در هر خط ابتدا id راس و سپس label آن می آید.
در بخش یال ها نیز که با Edges M* و یا Arcs M* مشخص می شود M نمایش دهنده ی تعداد یال های گراف است و M خط بعد همانند فرمت Link List تعریف می شود.
ورودی آزمایش شده ابتدایی شبکه ی کوچکی از فیسبوک با 4,039 راس و 88,234 یال و از هر دو نوع فرمت Link list و Pajek می باشد.
2.3.Methods of Implementation
در این قسمت به بررسی و انجام آزمایش الگوریتم های ارائه شده روی مجموع دادگان پرداخته شده و از کدهای موجود و آماده ی آنان استفاده شده است.
روش کامپایل و اجرای هر الگوریتم در فایل readme که داخل فولدر هر کدام قرار دارد آورده شده است.
-
1.2.3.Infomap
با انجام این روش بر روی دادگان facebook به نتایج و خروجی های زیر دست یافتیم.
تعداد ۷ انجمن پیدا شد که توسط ۱۲ یال با یکدیگر در ارتباطند. این ۷ انجمن با یکدیگر قابل ترکیب نیستند ولی توسط وزن یالی که بین آن هاست می توان تشخیص داد که چه مقدار به نسبت بقیه به یکدیگر شباهت دارند.

-
2.2.3.Combo
پس از انجام این روش بر روی دادگان facebook زمان زیادی را برای دریافت نتایج منتظر ماندم ( در حدود ۷۰ ثانیه ). در پایان کار نتایج و فایل خروجی این الگوریتم فایلی متنی است که تعداد خطوط آن به تعداد رئوس گراف می باشد و در هر خط تنها یک عدد نامنفی تولید شده است که نشان دهنده تعداد انجمن هایی است که راس مورد نظر در آن مشترک است.
تعداد انجمن ها و همچنین اعضای این انجمن ها جزو نتایج و خروجی برنامه نیست!! -
3.2.3.Louvain
نتایج خروجی برنامه ی نوشته شده برای متد Louvain به صورت یک فایل با فرمت tree. می باشد که باید به فرمت به clu. تبدیل شود چرا که برای نمایش خروجی به فرمت clu. نیازمندیم.
با انجام این روش بر روی دادگان facebook به تعداد 17 انجمن مختلف دست پیدا کردم که در شکل زیر قابل مشاهده می باشد.

4.2.3. Martelot
با اجرای متد Le Martelot بر روی دیتاست facebook به خروجی زیر دست پیدا کردیم.
این روش ۱۲ انجمن بر روی این دادگان پیدا کرد که در شکل زیر نمایان است.

نتیجه
تا اینجای کار روش های موجود را بر روی دادگان فیسبوک اجرا کردیم و برای هر کدام به نتایجی رسیدیم.
طبق تحقیقات دانشگاه MIT بر روی همین دادگان و مقایسه روش ها با یکدیگر به نمودار رسیده اند.

با توجه به این نمودار که از نظر کیفیت و سرعت متدهای مختلف بررسی شده اند متد Combo دارای بالاترین کیفیت و متد Martelot بالاترین سرعت را دارا بوده است.
نکته حائز اهمیت نبودن روش Infomap است که دلیلش رو نمیدونم!
با توجه به گستردگی زیاد این روش و همچنین داشتن کد بسیار قوی که از انواع فرمت های ورودی و خروجی را پشتیبانی می کند و دارای option زیادی برای اجرای آن است به همراه داکیومنت بسیار قوی و کامل، من استفاده از روش Infomap را درحال حاضر مناسب ترین روش برای پیدا کردن گروه های دوستان در شبکه های اجتماعی می دانم و به بقیه ی دوستان پیشنهاد می کنم.
منابع:
تشخیص گروه دوستان در شبکه اجتماعی، سینا خرمی
1-تعریف شبکه اجتماعی
تعاریف شبکه اجتماعی بسته به اعضا و روابط دخیل در آن از یکدیگر متمایز می شوند به نظر هر اجتماعی از گره ها و یالها،گرفته از پیوندهای پروتئینی،نحوه انتشار بیماری ها،جوامع موجودات زنده و انسانها می توانند به عنوان شبکه های اجتماعی در نظر گرفته شوند. برای مثالی از نمایش شبکه های اجتماعی می توان اعضای وبسایتهای اجتماعی را رئوس یک گراف و روابط دوستانه میان آنها را یالهای گراف دانست.
2-انواع روشهای استخراج جوامع
به طور کلی این روشها عبارتند از: 1-استفاده از پارامترهای ارزیابی کیفی و پارامترهای شباهت در استخراج جامعه؛ 2-استفاده از روشهای خوشه بندی؛ 3-بخش بندی گراف، 4-روشهای طیفی و 5-متدهای بیزین.
-
شناخت جوامع با پارامترهای شباهت: دراین روش جوامع بر اساس فاکتورهای کمی و کیفی شناسایی خواهند شد.از مهمترین پارامترهای کیفی می توان به ماژولاریتی اشاره ای داشت. این پارامترها مبنای مقایسه صحت بسیاری از الگوریتم های معرفی شده می باشند.زیرا که نحوه استفاده از آنها و فرمول مربرطه با معنای عمومی جوامع مطابق می باشد.جامعه در یک شبکه اجتماعی یعنی گروه متراکمی از اعضا که روابطی میان آنها حاکم میباشد ،این گروه بیشترین تعاملات را با افراد جامعه خود و کمترین روابط را با سایر اعضای شبکه خواهند داشت.
-
روش خوشه بندی: خوشه بندی نیز به معنای جدا کردن مناطق با تراکم بالا در مجموعه ویژگی ها تراکم کم از یکدیگر جدا می باشد. از این رو متناسب با معنای جامعه در شبکه هست.اصول خوشه بندی استفاده شده در استخراج جوامع نیز عموما مانند روشهای قبل، از شبکه ساخته شدهب هره می گیرند و سپس تکنیک های خوشه بندی جوامع را شناسایی خواهند کرد.استفاده از روشهای خوشه بندی هر چند سربار محاسباتی روش قبل را نخواهد داشت ،ولی محدودیت های خود خوشه بندی می تواند صحت جوامع را کاهش دهد.
-
روشهای طیفی: روشهای طیفی نیز حجم زیادی از تحقیقات در این زمینه را شامل می شوند،چرا که اصولا نتایج این دسته از الگوریتمها در مقایسه با روشهای شباهت از کیفیت بالاتری برخوردار هستند.در این روش براساس بردارهای ویژه ی ماتریس مجاورت یا ماتریس شباهت جوامع شناسایی می شوند به این صورت که k تعداد از برترین بردارهای ویژه به عنوان نقاط یک فضای k بعدی از گره های موجود شبکه تعریف می شوند و سپس الگوریتمهای کلاسیک خوشه بندی جوامع آنها را کشف می نماید،هر چند کیفیت این روش از روشهای خوشه بندی محض بیشتر می باشد ولی سربار محاسباتی بالایی نیز غالبا دارند.
-
متدهای بیزین: این دسته نیز غالبا با استفاده از توزیع دریکله به تشخیص جوامع کمک می کنند،این روش برای ایجاد جوامع مخصوصا از روی متون استفاده می شود.که جز پرهزینه ترین روشها از نظر محاسبات نیز به شمار می روند.این روش به کمک احتمالات افراد را در جوامع عضو می سازد.استفاده از این راهکار در اکثر روشهای ترکیبی نیز مشاهده می شود.
-
روشهای تکه بندی گراف: در روش تکه بندی گراف کل شبکه به محدوده هایی تقسیم می شود بدیهی است که هم پوشانی جایگاهی ندارد از طرفی غالبا الگوریتم های این روش از طریق دو دویی کردن شبکه به تقسیم آن می پردازند ،پس اگر نیاز به تشخیص سه جامعه باشد باید جامعه سوم از تقسیم یکی از دو جامعه قبلی حاصل شود،حال آنکه احتمالا اعضای این جامعه در بین دو گروه قبلی پخش هستند.علاوه بر محدودیت های بالا تعداد جوامع و حتی سایز آنها باید از پیش معلوم باشد.برای استفاده از این روش یک تابع شباهت را بسته به مختصات اعضا و یا شباهت رفتاری آنها و یا حتی از روشهای خوشه بندی نیز استفاده می کنند.
3-شناسایی عوامل موثر و نحوه ترکیب آنها جهت بهبود استخراج جوامع
به طور کلی برخی از چالش هایی متدهای تشخیص جوامع عبارتند از:
- مشخص نبودن بهترین الگوریتم برای تشخیص جامعه متناسب با نوع شبکه:تعداد زیادی از الگوریتم ها توسط محققین معرفی شده اند ولی تنها بر روی یک تعداد محدودی از شبکه ها با تعداد نودهای کم ارزیابی گشته اند که این خود اثباتی بر صحیح و جامع بودن آنها در تمامی شبکه های اجتماعی نمی باشد.
- پارامترهای اولیه ی ورودی برای الگوریتم ها: این پارامترها در بسیاری از موارد برای ما مشخص نیستند مثل تعداد جامعه ها،حداقل و حداکثر اعضای عضو هر جامعه،داشتن قابلیت هم پوشانی و ...
- محاسبات زیاد در تعیین مسیرها برای دسته ای از الگوریتم ها و محدودیت های خوشه بندی برای دسته دیگری از این الگوریتم ها کیفیت نتایج خروجی را تحت تاثیر قرار خواهند داد.
- کارا نبودن برخی از روشها برای شبکه های بزرگ از نظر مقیاس پذیری
با توجه به مطالب ذکر شده می توان منشا کاهش صحت تشخیص جوامع را در دو دلیل خلاصه نمود. 1.استفاده از منابع اطلاعاتی محدود در ایجاد شبکه 2.استفاده از راهکارهایی که به ذات محدودیتها و نواقصی در جهت تشخیص جوامع خواهند داشت.
1-3-استفاده از منابع مختلف(ناهمگن) برای شبکه های اجتماعی:
در مطالعات شبکه های اجتماعی این مورد به چشم می خورد.استفاده از منابع داده ای مختلف جوامع مجازی را حقیقی تر نمایش خواهند داد چرا که افراد ویژگیهای یکسانی ندارند و مقادیر متفاوتی را برای صفات خود دارا خواهند بود هم چنین تقریبا هیچگاه تنها یک نوع ارتباط با یکدیگر نخواهند داشت،مثلا در ساده ترین حالت دو نویسنده همکار احتمالا موضوعات تخصصی مرتبط با یکدیگر نیز خواهند داشت و یا به طریقی همکاران آنها نیز با یکدیگر ارتباط علمی دارند و یا خواهند داشت ؛ هم چنین مقالاتی که به این مقاله ارجاع داده اند از نظر محتوا شباهتی با این موضوع و در نتیجه با نویسندگان آن خواهند داشت.
روشهای تحلیلی موردی از این قائده استفاده نموده اند،در مورد مطالعه جوامع نویسندگان علمی استفاده از اطلاعات موجود در مقاله(کلمات کلیدی) به همراه استفاده از مقالات ارجاع داده شده به مقاله مذکور مورد استفاده قرار گرفته است و نتایج حاصل از آن حاکی از بالاتر رفتن دقت تشخیص جوامع بوده است. هم چنین در مورد مطالعه شبکه facebook استفاده از اطلاعات موجود در mini-feed که شامل - خلاصه ای از رویدادهای جدید دوستان و برنامه ها می باشد به -همراه اطلاعات گروههای دوستی به تشخیص جوامع حقیقی تر منجر شده است.
بسته به انواع منابع در نظر گرفته شده می توان روشهای استخراج جوامع را بکار گرفت،اگر نیاز به تفکیک روابط مختلف از یکدیگر نباشد و یا ویژگیهای هر گره تنها صفات آن به حساب آیند در نهایت می توان یک شبکه غنی داشت و در آن جوامع را استخراج نمود مانند دو نمونه ذکر شده ؛ ولی چنانچه انواع روابط میان اشخاص مهم باشد و هم چنین فضای داده ای از یک نوع تلقی نشود و یا اینکه نتوان انواع آنها را به یک نوع تبدیل نمود لازم است راهکارهای مجتمع نمودن منابع مختلف به گونه ای دیگر استفاده شود.
استفاده از منابع مختلف در شبکه پیچیدگی هایی نیز به همراه دارد،شناسایی منابع موثر،میزان تاثیر هر یک از این منابع وچگونگی در نظر گرفتن اجتماع و یا اختلاط این منابع با یکدیگر از جمله این پیچیدگی ها می باشد.
روشهای رایج در تکنیک استفاده از منابع مختلف:
1-استفاده از منابع مختلف در تعیین روابط و هم چنین غنی تر شدن گراف شبکه ای که در آن همه گره ها و روابط میان آنها از یک نوع فرض می شوند.(در مثال نویسندگان علمی با این تکنیک تفاوتی میان همکاران نویسنده و دستیاران آزمایشگاهی وجود نخواهد داشت و یا اینکه روابط شبکه های اجتماعی آنلاین می تواند بر اساس هریک از گروههای دوستی یا کامنت های روی عکسها و یا متن های بر روی صفحه شخصی افراد شناسایی شود.) در این حالت پس از ایجاد شبکه نیازی به حالت مجتمع کردن انواع منابع داده ای نخواهیم داشت.
2-استفاده از منابع مختلف سپس همگون کردن آنها و در نتیجه استخراج جوامع،برای این حالت می توان روابط
متعدد میان دو گره را با گراف وزن دار مشخص نمود هرچه روابط میان افراد بیشتر باشد یال ارتباطی میان آنها
وزن بیشتری خواهد داشت و یا در حالت دیگر چنان چه دو فرد با یک دیگر ارتباط داشته باشند شباهتهای متنی
آنها به عنوان وزن لینک ارتباطی تواند در نظر گرفته شود.هر چند به کار بستن این راهکار امکان پذیر است ولی
به جهت معنایی صحیح نمی باشد و از طرفی نحوه و تاثیر این تبدیلات همیشه مشخص نیست و ممکن است
کیفیت اطلاعات را کاهش دهد . برای این منظور می توان از پارامترهای شباهتی استفاده کرد که از نظر معنا نیزصحیح باشند.استفاده از پارامترهای co-citation یا coupling میتواند گراف شبکه نویسندگان علمی را بر اساس مقالات چاپ شده آنها ایجاد نماید.در واقع از یک پارامتر شباهت که با مفهوم و معنای سیستم مقالات و ارجاعات آنها نیز منطبق است برای ایجاد لینک های ارتباطی استفاده می شود هر چند این روش به خوبی در زمینه کتاب شناسی استفاده شده است اما باز هم نقصهایی بر شبکه از نظر اتصالات افراد خواهد داشت.
3-ایجاد شبکه های مختلف و یا در نظر گرفتن شبکه به عنوان گراف رنگی و سپس مجتمع نمودن انواع روابط از
روی گرافها و خروجی های آنها
4-استفاده از تکنیک های استخراج بر روی هر منبع داده به طور مجزا و سپس ترکیب جوامع شناخته شده ی مرحله قبلی
2-3-حداکثر کاهش ممکن خطاها و نواقص متدهای استخراج:
پس از اینکه روش انتخاب شده برای استخراج جوامع انتخاب شد،بهتر است برای رفع محدودیت های آن نیزاقدامی صورت گیرد. توجه زیاد محققین به این موضوع باعث شده تا پیشرفتهای زیادی الگوریتم های اولیه استخراج جوامع داشته باشند،استفاده از شبکه های جهت دار،وزن دار و هم پوشا از جمله این پیشرفت ها می باشد.
استفاده از پارامترهای کیفی ماژولاریتی: این پارامتر با وجود محبوبیت زیاد مخصوصا در شبکه هایی که حقیقت زمینهای 11 موجود نباشد محدودیت هایی نیز دارد.مثلا در هر شرایطی بیشترین مقدار ماژولاریتی بیانگر بهترین تقسیم شبکه نخواهد بود.
استفاده از روشهای خوشه بندی: الگوریتم های این دسته از قبیل k-means نیز وابسته هستند به مقادیر اولیه و چنانچه این پارامترها صحیح انتخاب نشوند روی نتایج نهایی تاثیر می گذارند، حتی اجرای الگوریتم خوشه بندی برای نقاط اولیه اگر چندین مرتبه هم اجرا شود مطمئن نخواهیم بود که بهترین نقاط اولیه را انتخاب نموده ایم. برای برطرف نمودن نقاط ضعف الگوریتم k-means روشی ارائه شده است که نقاط اولیه بر مبنای محاسبات قبلی انتخاب می شوند. در واقع فرض بر این است که گره های راهنما می توانند به عنوان نقاط اولیه انتخاب شوند،برای جلوگیری از انتخاب ناصحیح این گره های راهنما اشتراک جوامع اطراف هر راهنما محاسبه خواهد شد و بهترین گره ها و جوامع حاصله استخراج می شود.پس از ارزیابی مشاهده شده است که میزان صحت تشخیص توسط این الگوریتم بهبود یافته است.
از دیگر محدودیتهای خوشه بندی مشخص نمودن تعداد خوشه ها به عنوان پارامتر اولیه می باشد.(که تعداد آنها همیشه مشخص نیستند.) اگر خود شبکه خاصیت گروههای سلسله مراتبی را داشته باشد روشهای سلسله مراتبی موثر خواهند بود هر جند سر بار محاسباتی بالایی دارند در غیر این صورت باید چندین مرتبه الگوریتم را اجرا نمود و سپس بهترین عدد برای تعداد جوامع را انتخاب کرد. یکی دیگر از کاستی های روش خوشه بندی این است که خوشه ها عموما در سایز های خیلی بزرگ و یا خیلی کوچک ایجاد می شوند که در واقع نمی توان آنها را جامعه نامید.برای برطرف کردن این معایب می توان محدوده ای را برای اندازه خوشه ها در نظر گرفت.
یکی دیگر از روشهایی که می تواند نتایج بهتری را ارائه دهد،در نظر گرفتن تاثیرات تجمعی و کلی انواع الگوریتم های خوشه بندی می باشد و یا استفاده از یک نوع الگوریتم با پارامترهای ورودی متفاوت.
3-3-استفاده از ترکیب روشهای استخراج جوامع
استفاده از روشهای ترکیبی در زمینه های بازیابی اطلاعات(15)،سیستم های پیشنهاد دهنده(17 و 16) و خزنده های وب(25 و 18) و هم چنین برای طبقه بندی و خوشه بندی داده های وب (19 و 21 و 25) و نتایج موتورهای جستجو(13) استفاده شده است. جدول(1) خلاصه ای از برخی تحقیقات در این زمینه را ارائه میکند.

استفاده از چند روش به صورت ترکیبی در شبکه های اجتماعی موضوعی است که اخیرا به آن پرداخته شده است. علاوه بر این که استفاده از ترکیب روشهای استخراج می تواند جوامع یکنواخت تری را حاصل کند گاهی مجبور هستیم به دلیل این که منابع موجود از انواع مختلفی هستند از روش متناسب با هر نوع داده استفاده کنیم و سپس با راهکار مناسبی آنها را ترکیب نماییم. در ادامه به معرفی چند روش ترکیبی می پردازیم:
ترکیب الگوریتم های مختلف برای بهبود هر یک از روشهای منفرد: در (22) یک چارچوب برای روش ترکیبی تشخیص جوامع ارائه شده است این چارچوب از روش تخصیص پنهان دریکله 15 بر روی گراف از روشهای بیزین استفاده می کند،می توان چندین الگوریتم تشخیص جامعه را با هم به کار برد و نتایج نهایی را بهبود بخشید.این چارچوب براساس تخمین لینکها قادر است تا آشفتگیهای کوچکی در لینکها را نیز تشخیص دهد.در این چارچوب طی دو مرحله از الگوریتمهای تشخیص جامعه استفاده می شود.که نتایج مرحله اول به عنوان ورودی مرحله بعدی مورد استفاده قرار خواهند گرفت.الگوریتم مرحله اول می تواند از هر نوعی باشد اما در مرحله دوم از حالت گسترش یافته روش LDA_G استفاده می شود .این روش نسبت به LDA_G عادی ،صفات لینکها را هم به همراه دارد.اطلاعات مرحله اول برای پیکر بندی اولیه روش LDA_G گسترش یافته، استفاده می شوند که پس از آن می توانند این اطلاعات نادیده فرض شوند و یا در مرحله دوم نیز استفاده شوند.این روش ترکیبی باعث می شود تا استفاده از الگوریتم مرحله اول پیکر بندی فاز دوم را بهبود بخشد و روش دوم نیز چارچوب را بی نیاز از تعیین تعداد جوامع می سازد.
ترکیب منابع مختلف برای بالابردن مقیاس پذیری(استفاده از منابع دیگر برای کاهش سربار محاسبات و یا فاسیر منبع داده ای اصلی): در (29) هدف، استخراج جوامع با موضوعات 18 شبیه پنهان می باشد،از آنجا که این عمل در فضای داده های حجیم امکان پذیر نیست و از طرفی متن نویسندگان عموما دارای ارجاعاتی می باشد که مرتبط به متن کنونی آنهاست.پس با استفاده از روابط و از روی ساختار 19 موجود در متن الگوریتمهای ساختاری می توان با روشهای – -تر و مقیاس پذبرتر به تشخیص این جوامع پرداخت.)عموما یک جامعه شناخته شده از طریق ساختار شامل چندین موضوع مشترک می باشند.(با کمک روابط ابتدا هسته های جامعه 21 تشخیص داده می شوند سپس برای یکنواخت سازی جوامعی که با کمک این هسته ها ایجاد خواهند شد روش ادغامی بر اساس شباهتهای موضوعی معرفی شده است الگوریتم مبتنی - بر متن - . در مرحله نهایی با کمک طبقه بندی صفاتی که از متن به دست آمده اند عضویت اعضا را در جوامع خود تایید و یا رد می نماید.
ترکیب منابع مختلف برای فشرده سازی و بهبود صحت نتایج: روش (23) از ترکیب روابط داده ها و صفات هر گره به خوشه بندی گره ها پرداخته است.با ایجاد ماتریس مجاورت و الحاق بردار وزن به هر یک از درایه های آن روابط و صفات گره ها در نظر گرفته خواهند شد.
پارامتر (silhouette coefficient (24 برای تعیین کیفیت خوشه ها مستقل از تعداد آنها به کار می رود.از آنجا که فرض می شود هر جامعه از نظر روابط به هم مرتبط هستند با کمی تغییر این پارامتر متناسب برای استفاده در جوامع شده است و به همین دلیل در این مقاله به عنوان پارامتر ارزیابی سنجش استفاده شده است.
الگوریتم ارائه شده در(23) مانند الگوریتم k-means حساس به گره های مرکزی ابتدایی می باشد.به همین دلیل راهکاری جهت به حداقل رساندن آنها استفاده شده است که عبارت است از استفاده از تعداد گره های مرکزی بیش از تعداد خوشه ها و تضمین این موضوع که هر خوشه حقیقی حداقل یک گره مرکزی دارد. الگوریتم JoinClust برای حل مسئله خوشه بندی تعداد خوشه متصل به هم به کار می رود.این روش از روشهای اکتشافی پایین به بالا می باشد که بینیاز از دانستن تعداد خوشه ها خواهد بود.در مرحله اول این الگوریتم اتمهای خوشه ها )هر اتم شامل یک گره مرکزی و همسایگان آن می باشد( مشخص می شوند، از آنجا که هر خوشه حداقل یک اتم خواهد داشت می توان اطمینان داشت که تمام خوشه ها شناخته خواهند شد.هر گره به صورت حریصانه به خوشه اضافه می شود تنها اگر متصل به یکی از اعضای خوشه ها )در نظر داشتن روابط میان گره ها( با کمترین فاصله)فاصله از نظر صفات گره ها با همدیگر( باشد سپس یک مرحله پالایش برای بالا بردن کیفیت گره های مرکزی استفاده می شود و در نهایت در مرحله دوم این اتم ها بر اساس پارامتر معرفی شده ادغام خواهند شد.از آنجا که اتم ها کوچکترین مولفه برای خوشه ها هستند ،در واقع گراف تا حدی برای مرحله ادغام فشرده شده است.در نتیجه این روش یک درجه زمان اجرای روشهای سلسله مراتبی را کاهش داده و به رسانیده است. بر اساس آزمایشهای صورت گرفته ثابت شده که استفاده از اطلاعات مکمل یکدیگر قدرت (O(n2 تشخیص تعداد و تعیین خوشه های صحیح را افزایش خواهد داد.
خلاصه و جمع بندی:
در این مقاله مسئله استخراج جوامع در شبکه های اجتماعی با در نظر گرفتن منابع موثر و نحوه ترکیب آنها با یکدیگر مورد بحث و بررسی قرار گرفت.جدول دو خلاصه روشهای ترکیبی در شبکه های اجتماعی را معرفی می کند.
با توجه به گسترش روزافزون اطلاعات در شبکه های اجتماعی ، شناسایی این قبیل شبکه ها و هم چنین استخراج جوامع پنهان در آن بسیار حائز اهمیت می باشد لذا پس از آشنایی با محیط مورد تحلیل لازم است تا نیازمندی های الگوریتم استخراج شناسایی شود.این نیازمندی ها موردی می باشند ، در حقیقت معنای جامعه در این مرحله شکل میگیرد و بسته به آن هر یک از موارد ذیل می تواند در شبکه و جوامع آن لحاظ شود و یا اینکه با توجه به نوع محیط و یا دلیل استخراج جوامع مورد نیاز نباشند، ویژگی هایی از قبیل:در نظر گرفتن صفات اعضا،داشتن انواع روابط،روابط نا متقارن ،جوامع با خاصیت سلسله مراتبی و یا قابلیت همپوشا،تاثیرات مختلف فاکتورها بر روی وزن دهی،دانستن تعداد جوامع از پیش و... هم چنین نوع صفات و انواع داده ای برای نمایش آنها روشهای مختلفی را می طلبد.پس انتخاب روش و الگوریتم برای یافتن جوامع موجود بدون شناخت محیط و هم چنین بدون در نظر گرفتن نحوه کارکرد هر روش غیرممکن خواهد بود.
مهمترین موضوع پس از انتخاب منابع جهت استخراج جوامع نحوه ی ترکیب و استفاده از آنها می باشد. برای این
منظور تکنیک هایی از قبیل تغییر انواع صفات به یک حالت و یا در نظر گرفتن هر کدام از آنها به صورت مستقل و سپس مجتمع کردن آنها مورد استفاده قرار می گیرند.هر چند میزان تاثیر هر بعد از این مدل های ترکیبی هنوز واقعا مشخص نیست و بسته به نظر تحلیلگر شبکه انتخاب خواهند شد. در قسمت 3-3 جدیدترین و موثرترین روشهای ترکیب منابع و - روشهای ترکیب الگوریتم ها برای بهبود خاصیت مقیاس پذیری و یا بالابردن صحت نتایج معرفی شده اند. در نهایت پیشنهاد می شود چنانچه شبکه از لحاظ موقعیت مطالعاتی نیز مورد اهمیت می باشد، از همان ابتدا در حین گردآوری اطلاعات اعضا در زمان عضویت و فعالیت آنها، اطلاعات و داده های لازم برای تحلیل آتی نیز در فرمت مناسب گردآوری و در پایگاهی به ثبت برسند.

منابع:
شناسایی عوامل موثر و نحوه ترکیب آنها برای تشخیص جوامع در شبکه های اجتماعی، مهرآفرین آدمی دهکردی، محمد حسین ندیمی، رضا قائمی
.: Weblog Themes By Zabihi :.